log_scriptmon.ini
[constant]
monitored_file = /home/pi/logmonitor/test_events.log
counter_file = /home/pi/logmonitor/log_scriptmon.counter
script_logfile = /home/pi/logmonitor/log_scriptmon.log
max_run_diff = 600
[logfile]
# you have to prefer to combine search pattern as (MAJOR|CRITICAL|FATAL) instaed# to define more pattern in single lines
# example pattern1 = (MAJOR|CRI.*CAL|FATAL)
pattern1 = IN.O
pattern2 = CRITI.+
pattern3 = FATAL
log_scriptmon.py
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# log_scriptmon.py
# Skript zum Monitoring von LOG-Dateien
#
import os
import sys
import hashlib
import re
import time
import configparser
def read_configfile(fullfilepath):
configuration = configparser.ConfigParser()
configuration.read(fullfilepath)
return configuration
def file_exist(fullfilepath, error_return = 0):
if not os.path.isfile(fullfilepath):
if error_return:
print(f"ERROR: file {fullfilepath} does not exist. EXIT {error_return}")
sys.exit(error_return) # Beende das Programm mit einem Fehlercode
else:
print(f"Situation G - Die Datei {fullfilepath} existiert nicht.")
return False
return True
def datei_groesse(fullfilepath):
if os.path.isfile(fullfilepath):
groesse = os.path.getsize(fullfilepath)
return int(groesse)
else:
return -1 # Fehlercode, wenn die Datei nicht existiert
def get_basename():
skript_name = sys.argv[0]
dummy = skript_name.split("/")
x = len(dummy) - 1
skript_name = dummy[x]
dummy = skript_name.split(".")
skript_name = dummy[0]
# print(skript_name)
return skript_name
def linecounter(fullfilepath):
with open(fullfilepath, 'r') as file:
anzahl_zeilen = sum(1 for zeile in file)
return int(anzahl_zeilen)
def calc_checksum(fullfilepath, algorithm="sha256"):
# Öffne die Datei im Binärmodus und lese den Inhalt
with open(fullfilepath, 'rb') as datei:
# Wähle den gewünschten Hash-Algorithmus
hash_algorithm = hashlib.new(algorithm)
# Lese die Datei blockweise und aktualisiere den Hash
blockgroesse = 4096 # Zum Beispiel 4 KB pro Block
for block in iter(lambda: datei.read(blockgroesse), b''):
hash_algorithm.update(block)
# Gib die hexadezimale Darstellung der Checksumme zurück
checksum = hash_algorithm.hexdigest()
return checksum
def write_counterfile(fullfilepath,counterarray):
with open(fullfilepath, 'w') as file:
for element in counterarray:
file.write(str(element) + '\n')
return
def read_counterfile(fullfilepath):
with open(fullfilepath, 'r') as file:
counterarray = [line.rstrip() for line in file.readlines()]
return counterarray
def search_in_file(search_pattern, fullfilepath,start_seek = 0):
with open(fullfilepath, 'r') as file:
file.seek(start_seek)
for line in file:
for pattern in search_pattern:
if re.search(pattern, line.strip(), re.IGNORECASE):
print(f'MATCH:{line.strip()}')
return
def log(logtxt, fullfilepath):
with open(fullfilepath, 'a') as file:
logtxt = logtxt.strip()
file.write(str(logtxt) + '\n')
return
if __name__ == "__main__":
################################################
# MAIN
################################################
# READ THE INI-/CONFIGFILE
basename = get_basename() # scriptname
scriptdir = '/home/pi/logmonitor/' # scriptdir
configfile = scriptdir + basename + ".ini" # ini-file
file_exist(configfile,2) # check file exists, exit 2
cfg = read_configfile(configfile) # read ini-file/config into cfg structure
monitoredfile = cfg.get("constant", "monitored_file") # monitored logfile
counterfile = cfg.get("constant", "counter_file") # temporary data
logfile = cfg.get("constant", "script_logfile") # logfile of this script
max_run_diff = int(cfg.get("constant", "max_run_diff")) # max Zeitdiff.zw.2 Läufen
# SEARCH PATTERN
search_pattern = []
for i in range(1, 9):
pattern_key = f"pattern{i}"
if cfg.has_option("logfile", pattern_key):
search_pattern.append(cfg.get("logfile", pattern_key))
else:
break # ende der schleife, wenn ein pattern nicht mehr gefunden wird
# Standard Suchpattern, wenn kein pattern gefunden wurden
if not search_pattern:
search_pattern.append(".*")
print("start ... ")
print(f'Cache : {counterfile}')
print(f'Search Pattern: {search_pattern}')
# print(" ".join(map(str, search_pattern)))
file_exist(monitoredfile,1) # existiert logfile nicht, exit 1
print(f'Monitor on {monitoredfile}')
if file_exist(counterfile,0):
counterarray_last = read_counterfile(counterfile)
else:
counterarray_last = ["0", "0", "0", "0"]
checksum_last = counterarray_last[0]
filesize_last = int(counterarray_last[1])
anzlines_last = int(counterarray_last[2])
lastrund_last = int(counterarray_last[3])
checksum_curr = calc_checksum(monitoredfile) # C1 current checksum
filesize_curr = datei_groesse(monitoredfile) # C2 filesize
anzlines_curr = linecounter(monitoredfile) # C3 linecount
lastrund_curr = int(time.time()) # C4 last rundate
run_diff = lastrund_curr - lastrund_last
write_counterfile(counterfile,[checksum_curr, filesize_curr, anzlines_curr, lastrund_curr])
print('---------------------')
print(f'checksum_last: {checksum_last}')
print(f'filesize_last: {filesize_last} Bytes')
print(f'anzlines_last: {anzlines_last}')
print(f'lastrund_last: {lastrund_last}')
print('---------------------')
print(f'checksum_curr: {checksum_curr}')
print(f'filesize_curr: {filesize_curr} Bytes')
print(f'anzlines_curr: {anzlines_curr}')
print(f'lastrund_curr: {lastrund_curr}')
print('---------------------')
# Decision Section
if (run_diff > max_run_diff):
print(f"Situation A - first or new start with time difference over {max_run_diff} s, set seek to current file size and wait for next intervall.")
elif (checksum_last == checksum_curr):
print("Situation B - old and current file identical, nothing to do")
elif (checksum_last == "0") and (checksum_last != checksum_curr) \
and (filesize_last == 0) and (filesize_last < filesize_curr):
print("Situation C - new file, read from start")
search_in_file(search_pattern, monitoredfile, 0)
elif (anzlines_last < anzlines_curr):
print("Situation D - normal growing file, read from last position")
search_in_file(search_pattern, monitoredfile, filesize_last)
elif (anzlines_last > anzlines_curr) and (filesize_curr == 0):
print("Situation E - logrotate, new file empty - nothing to do")
elif (anzlines_last > anzlines_curr):
print("Situation F - logrotate, read file from start")
search_in_file(search_pattern, monitoredfile, 0)
print(" ... ende ")
Um eine Nachricht mit Python in das Systemprotokoll /var/log/messages zu schreiben, kannst du die syslog-Bibliothek in Python verwenden. Das hier ist ein einfaches Beispiel:
import syslog
def schreibe_in_messages_nachricht(nachricht):
syslog.syslog(syslog.LOG_INFO, nachricht)
# Beispielaufruf
nachricht = "Dies ist eine Testnachricht für /var/log/messages"
schreibe_in_messages_nachricht(nachricht)
Dieses Beispiel verwendet die Funktion syslog() aus der syslog-Bibliothek. Der zweite Parameter ist der Prioritätswert, der in diesem Fall auf syslog.LOG_INFO gesetzt ist. Du kannst den Prioritätswert entsprechend deinen Anforderungen anpassen. Hier sind einige häufig verwendete Werte:
syslog.LOG_EMERG: Systemausfall – nur für extreme Situationen verwenden.
syslog.LOG_CRIT: Kritische Situationen, die möglicherweise das System beschädigen.
syslog.LOG_ERR: Fehler, die behoben werden müssen.
syslog.LOG_WARNING: Warnungen, die auf Probleme hinweisen.
syslog.LOG_NOTICE: Normale, aber wichtige Ereignisse.
syslog.LOG_INFO: Reine Informationsmeldungen.
syslog.LOG_DEBUG: Debugging-Informationen.
Bitte beachte, dass das Schreiben in /var/log/messages normalerweise erweiterte Berechtigungen erfordert, und dein Programm möglicherweise Root-Rechte benötigt. Sei vorsichtig, wenn du Protokolle manipulierst, die Root-Berechtigungen erfordern.
Du kannst mit der syslog-Bibliothek in Python Nachrichten in benutzerdefinierte Protokolldateien schreiben. Dabei wird normalerweise die Funktion openlog() verwendet, um die aktuelle Programmkennung und die gewünschte Option festzulegen. Anschließend kannst du syslog() verwenden, um Nachrichten zu dieser Protokolldatei hinzuzufügen. Hier ist ein Beispiel:
import syslog
# Öffne das benutzerdefinierte Protokoll
syslog.openlog("meine_app", syslog.LOG_PID, syslog.LOG_LOCAL0)
def schreibe_in_custom_log(nachricht):
syslog.syslog(syslog.LOG_INFO, nachricht)
# Beispielaufruf
nachricht = "Dies ist eine Nachricht für mein benutzerdefiniertes Protokoll"
schreibe_in_custom_log(nachricht)
In diesem Beispiel wird syslog.openlog(„meine_app“, syslog.LOG_PID, syslog.LOG_LOCAL0) verwendet, um das benutzerdefinierte Protokoll zu öffnen. „meine_app“ ist die Programmkennung, syslog.LOG_PID gibt an, dass die PID in die Protokolldatei aufgenommen werden soll, und syslog.LOG_LOCAL0 gibt das Protokoll-Fazilitätslevel an.
Dann wird die syslog()-Funktion wie zuvor verwendet, um Nachrichten in das benutzerdefinierte Protokoll zu schreiben. Du kannst die Programmkennung, das Fazilitätslevel und andere Optionen nach Bedarf anpassen.
Stelle sicher, dass das Verzeichnis und die Protokolldatei, die du auswählst, die entsprechenden Berechtigungen haben, damit das Schreiben erfolgreich ist.
Auf einem Mac lässt sich für Test- und Lernzwecke eine Mini-Virtualisierungsumgebung einrichten die aus einem vCenter und x beliebigen ESXi Servern besteht. Hoch-Verfügbarkeit wäre auch denkbar aber dazu später eventuell was.
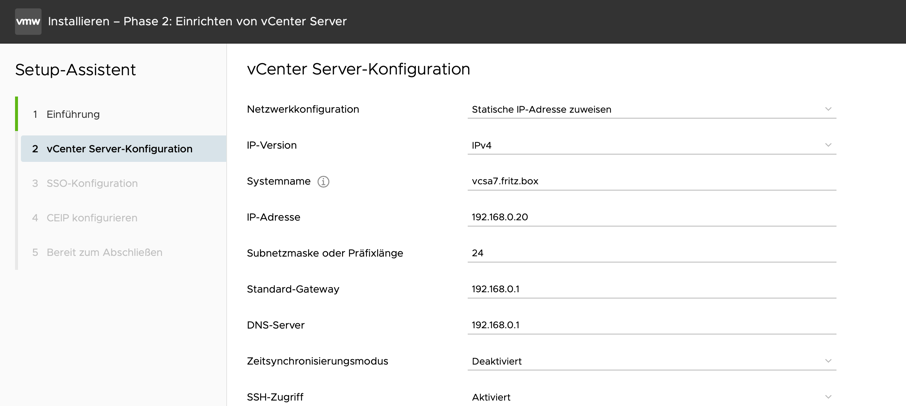
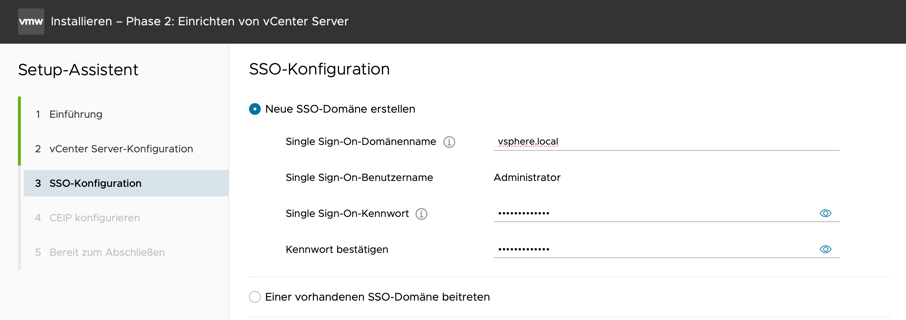
Vorab sollte man sich paar Gedanken über die IP-Adresse, Hostname und Domain-Name machen. Es ist relativ kompliziert diese Parameter nach der Installation anzupassen da einige interne Zertifikate geändert werden müssen und das ist eine Geschichte für sich.
Zuerst muss das runtergeladene VCSA ISO File gemountet werden.
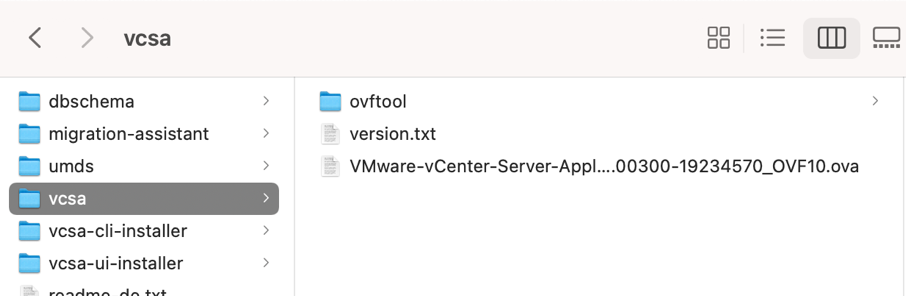
Mit dem Finder in den Ordner VSCA des gemounteten Images wechseln und das *.ova File lokal auf die Festplatte kopieren:
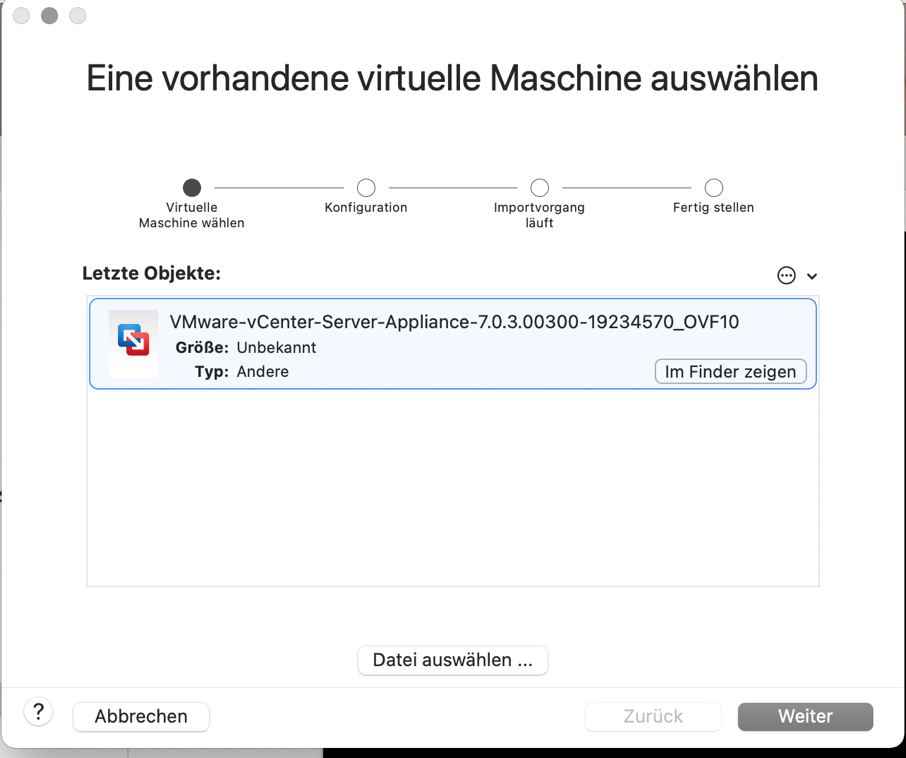
In Fusion unter Ablage auf Importieren klicken
Hier muss jetzt das OVA-File eingebunden werden und auf weiter klicken:
Eine der angebotenen Ausführungen auswählen. Da das alles nur zum Spielen ist wählen wir Tiny vCenter with embaded PSC
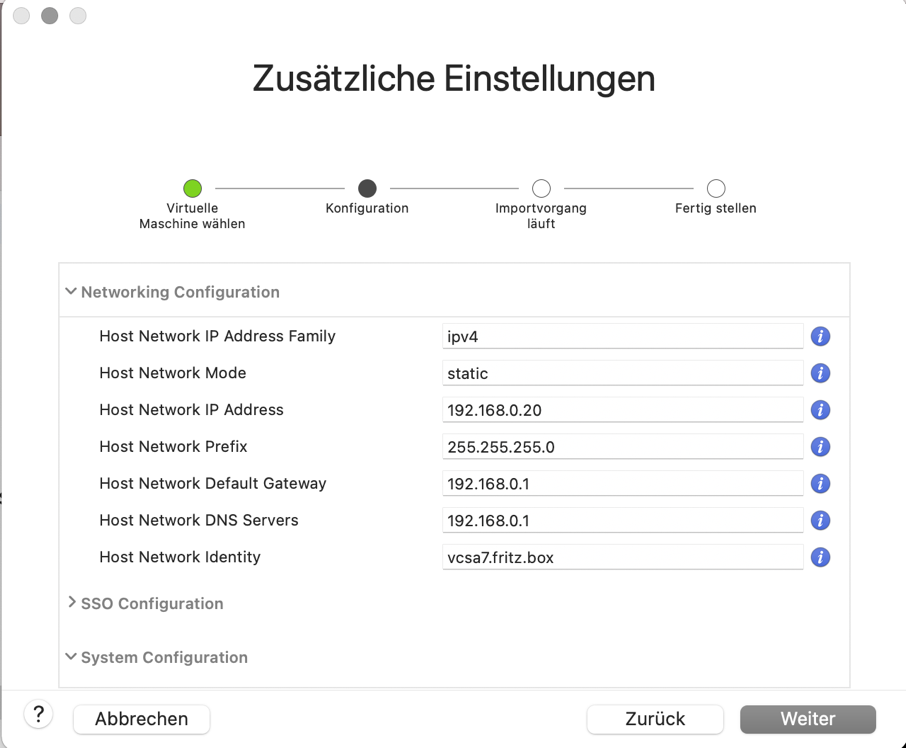
Im nächsten Schritt zusätzliche Einstellungen eingetragen. Hier die Network Configuration
Den Ablageort der VM auswählen und den Importvorgang starten
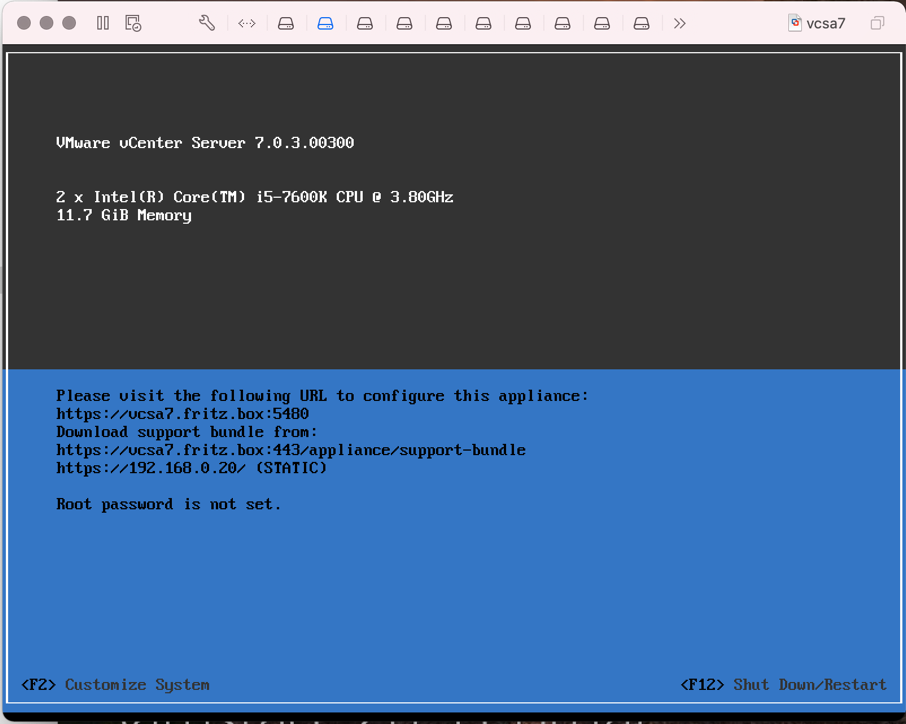
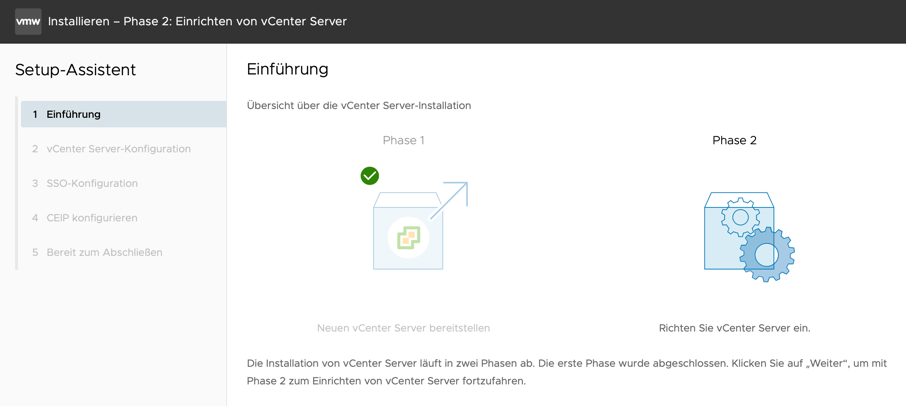
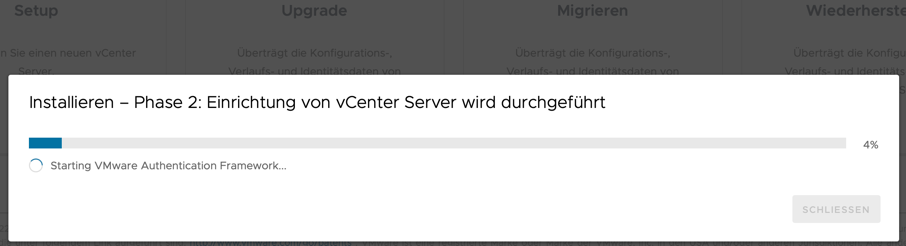
Nun kann die neu erstellte VM gestartet werden. Nachdem die VM erstmalig gebootet wurde werden im Hintergrund Einstellungen vorgenommen. Nach kurzer Zeit rebootet die VM.
Nachdem die VCSA neu gebootet wurde muss in der Konsole das Passwort gesetzt werden. Dazu F2 drücken, es erscheint das Dialog zum Ändern des PWs
Der Rest der Installation erfolgt im Browser. Dazu die IP-Adresse der VCSA und den Port 5480 über https aufrufen:
https://<VCSA Name>:5480/
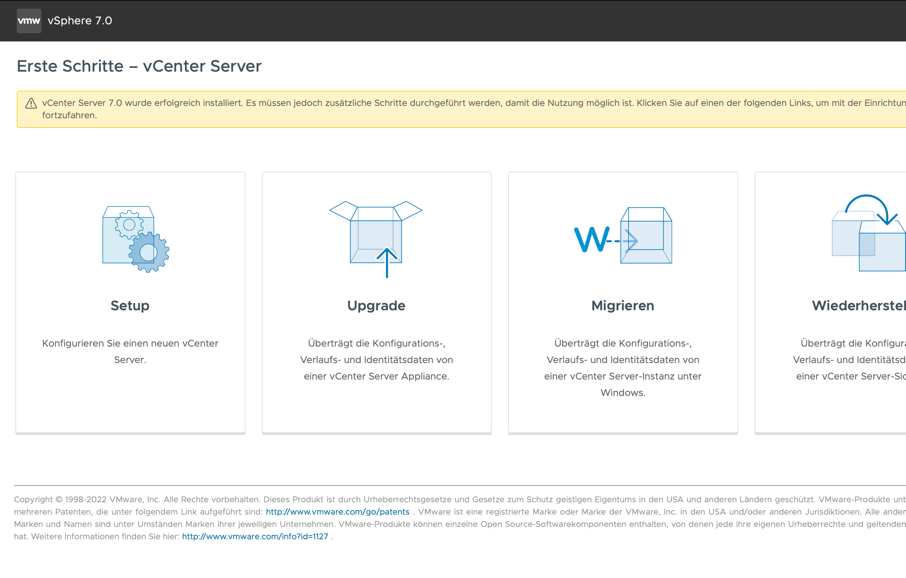
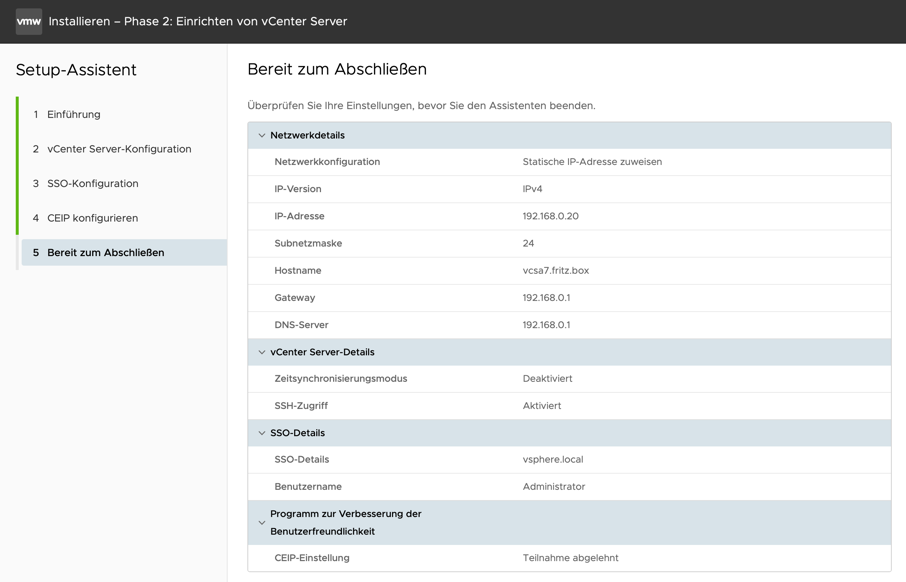
Setup starten
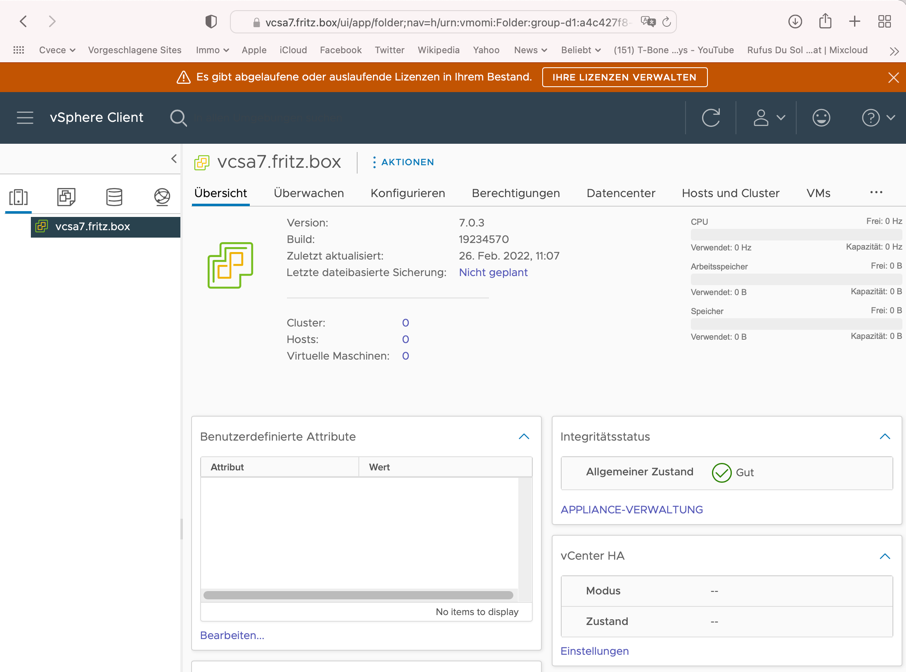
Nachdem alles installiert ist kann die vCenter GUI im Browser unter der Adresse des vCenters geöffnet werden:
(6) Eine Steuerdatei (Unit File) für systemd anlegen für Apache Tomcat Ermitteln des JAVA-Pfad mit sudo alternatives –list | grep ^java und Verwendung in der Unit-Datei als JAVA_HOME Umgebungsvariable
● tomcat.service - Apache Tomcat Server 10
Loaded: loaded (/etc/systemd/system/tomcat.service; enabled; vendor preset: disabled)
Active: active (running) since Mon 2022-02-07 17:16:13 CET; 36s ago
Main PID: 49244 (java)
Tasks: 30 (limit: 4770)
Memory: 105.7M
CGroup: /system.slice/tomcat.service
└─49244 /usr/bin/java -Djava.util.logging.config.file=/opt/tomcat/conf/logging.properties -Djava.util.logging.manager=org>
Feb 07 17:16:13 Rocky8 systemd[1]: Starting Apache Tomcat Server 10...
Feb 07 17:16:13 Rocky8 systemd[1]: Started Apache Tomcat Server 10.
(7) Firewall freischalten für den Port 8080 Standardmäßig wird die öffentliche Zone (public) verwendet. Andernfalls mit dem Parameter –zone=internal wie hier die interne Zone spezifizieren.
sudo firewall-cmd --add-port=8080/tcp --permanent
success
sudo firewall-cmd --reload
Success
sudo firewall-cmd --info-zone=public
public (active)
target: default
icmp-block-inversion: no
interfaces: ens160
sources:
services: cockpit dhcpv6-client ssh
ports: 8080/tcp
protocols:
forward: no
masquerade: no
forward-ports:
source-ports:
icmp-blocks:
rich rules:
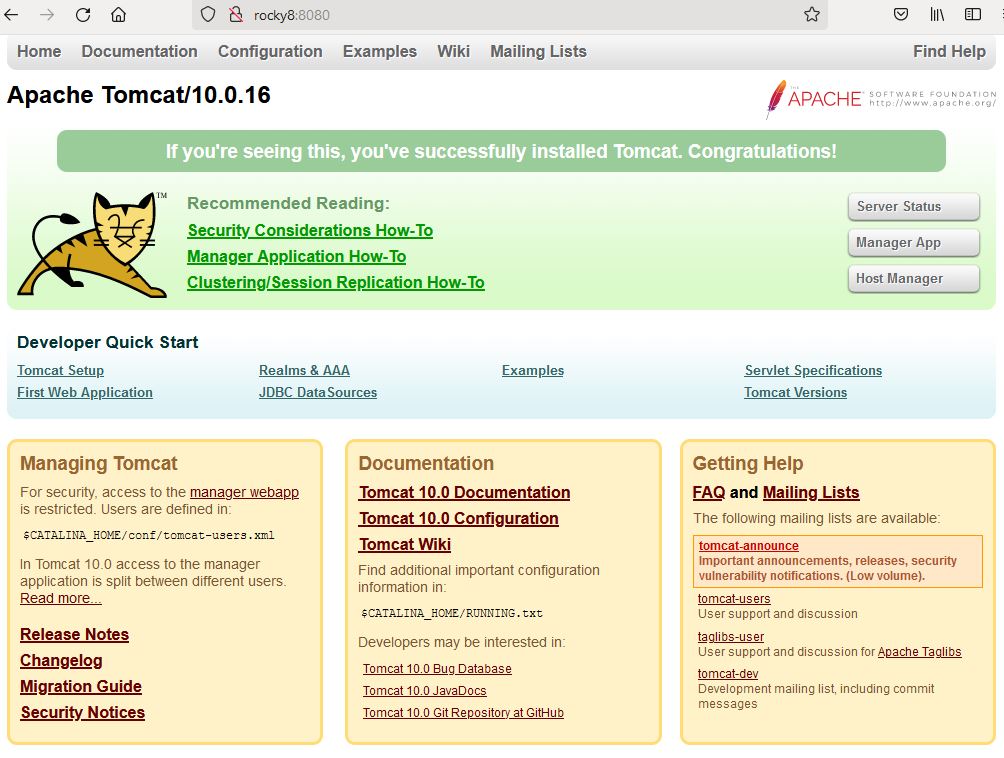
Startseite des Tomcat, Aufruf mit http:/<servername>:8080
Jetzt ist unser Tomcat über explizite Angabe des Ports 8080 erreichbar. Das kann man so machen. muss man aber nicht. Schöner ist es, die Kommunikation auf Port 80 umzulegen.
$ sudo apt-get install apt-transport-https
...
$ wget -qO- https://repos.influxdata.com/influxdb.key | sudo apt-key add -
OK
$ source /etc/lsb-release$ echo "deb https://repos.influxdata.com/${DISTRIB_ID,,} ${DISTRIB_CODENAME} stable" | sudo tee /etc/apt/sources.list.d/influxdb.list
deb https://repos.influxdata.com/ubuntu focal stable
$ sudo apt-get update && sudo apt-get install telegraf
...
Reading package lists… Done
Building dependency tree
Reading state information… Done
The following NEW packages will be installed:
telegraf
0 upgraded, 1 newly installed, 0 to remove and 13 not upgraded.
...
Preparing to unpack …/telegraf_1.19.1-1_arm64.deb …
Unpacking telegraf (1.19.1-1) …
Setting up telegraf (1.19.1-1) …
Created symlink /etc/systemd/system/multi-user.target.wants/telegraf.service → /lib/systemd/system/telegraf.service.
Dienst starten
$ systemctl start telegraf
Statusabfrage
$ systemctl status telegraf● telegraf.service - The plugin-driven server agent for reporting metrics into InfluxDB
Loaded: loaded (/lib/systemd/system/telegraf.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2021-07-20 22:23:30 CEST; 32min ago
Docs: https://github.com/influxdata/telegraf
Main PID: 1686 (telegraf)
Tasks: 10 (limit: 973)
CGroup: /system.slice/telegraf.service
└─1686 /usr/bin/telegraf -config /etc/telegraf/telegraf.conf -config-directory /etc/telegraf/telegraf.d
Telegraf konfigurieren: Konfigurationsdatei: /etc/telegraf/telegraf.conf (zunächst als default durch Installation angelegt) Anzeige der Konfiguration und schreiben in eine Kopie im aktuellen Verzeichnis
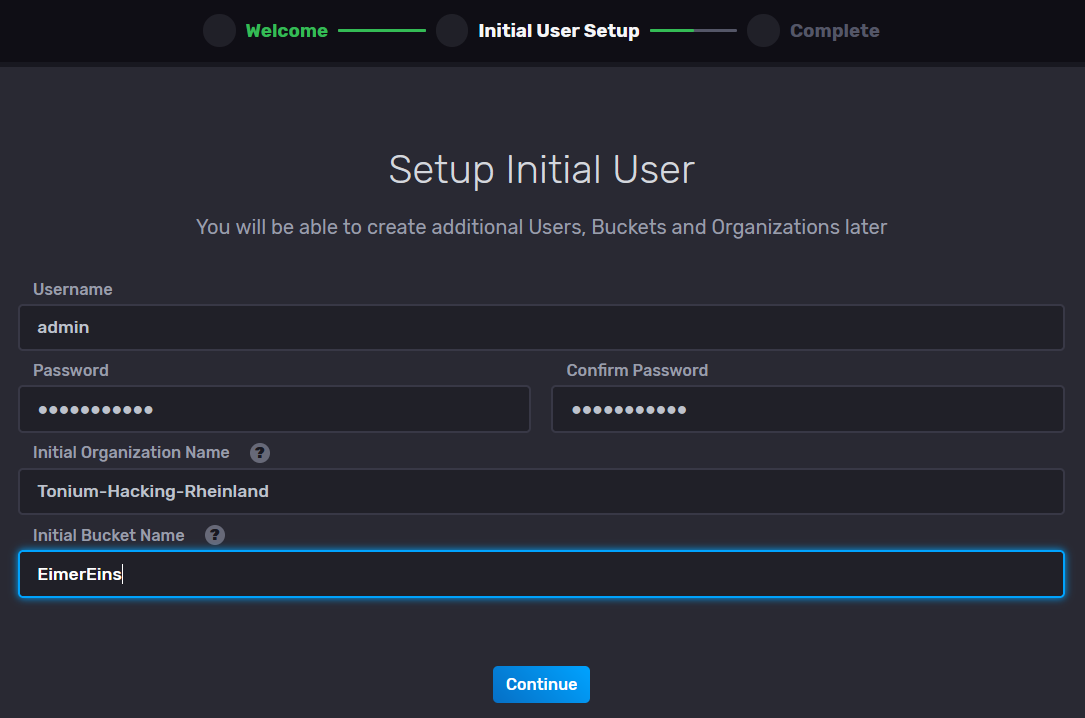
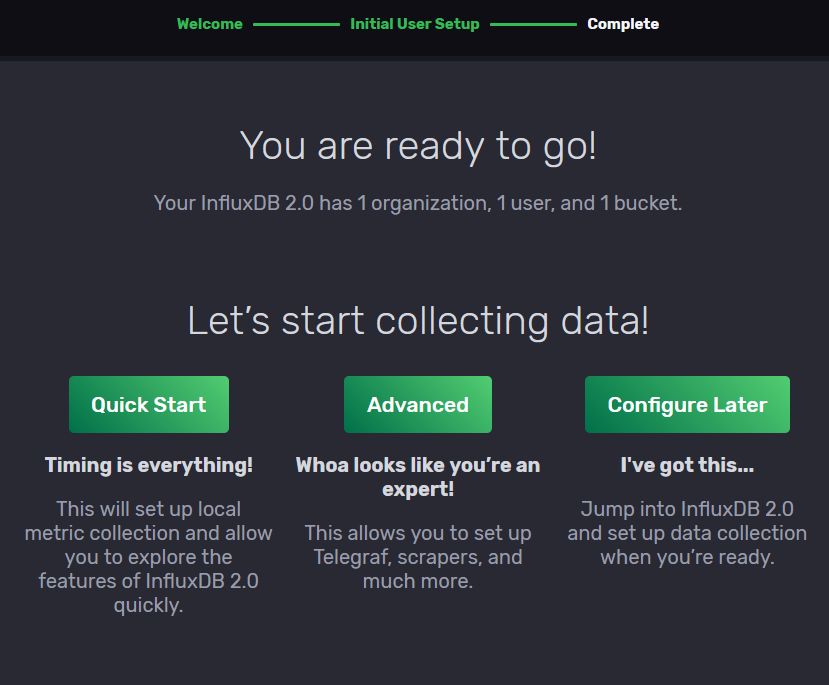
Stichpunkte zur Installation InfluxDB V2.0.7 auf Raspberry Pi mit Ubuntu (arm64)
Download des entsprechenden Paketes in das aktuelle Verzeichnis
$ wget https://dl.influxdata.com/influxdb/releases/influxdb2-2.0.7-arm64.deb
...
HTTP request sent, awaiting response… 200 OK
Length: 112830606 (108M) [application/octet-stream]
Saving to: ‘influxdb2-2.0.7-arm64.deb’
...
$ ls -l
-rw-rw-r-- 1 ubuntu ubuntu 112830606 Jun 4 21:40 influxdb2-2.0.7-arm64.deb
Installieren des Package und Erzeugen der Symlinks für systemd
$ sudo dpkg -i influxdb2-2.0.7-arm64.deb
Selecting previously unselected package influxdb2.
(Reading database … 118966 files and directories currently installed.)
Preparing to unpack influxdb2-2.0.7-arm64.deb …
Unpacking influxdb2 (2.0.7) …
Setting up influxdb2 (2.0.7) …
Created symlink /etc/systemd/system/influxd.service → /lib/systemd/system/influxdb.service.
Created symlink /etc/systemd/system/multi-user.target.wants/influxdb.service → /lib/systemd/system/influxdb.service.
Prüfen ob der influxdb Dienst läuft (ggf. nach reboot)
$ systemctl status influxdb
● influxdb.service - InfluxDB is an open-source, distributed, time series database
Loaded: loaded (/lib/systemd/system/influxdb.service; enabled; vendor preset: enabled)
Active: active (running) since Sun 2021-07-18 12:54:56 CEST; 3min ago
Docs: https://docs.influxdata.com/influxdb/
Main PID: 1663 (influxd)
Tasks: 9 (limit: 973)
CGroup: /system.slice/influxdb.service
└─1663 /usr/bin/influxd
Konfigurationsdatei für den Dienst ist /lib/systemd/system/influxdb.service:
[Unit]
Description=InfluxDB is an open-source, distributed, time series database
Documentation=https://docs.influxdata.com/influxdb/
After=network-online.target
[Service]
User=influxdb
Group=influxdb
LimitNOFILE=65536
EnvironmentFile=-/etc/default/influxdb2
ExecStart=/usr/bin/influxd
KillMode=control-group
Restart=on-failure
[Install]
WantedBy=multi-user.target
Alias=influxd.service
Datenverzeichnis für die Zeitreihendaten (time series data) /var/lib/influxdb/engine/
Datei für die Schlüsselwerte ( key-value-data ) – /var/lib/influxdb/influxd.bolt